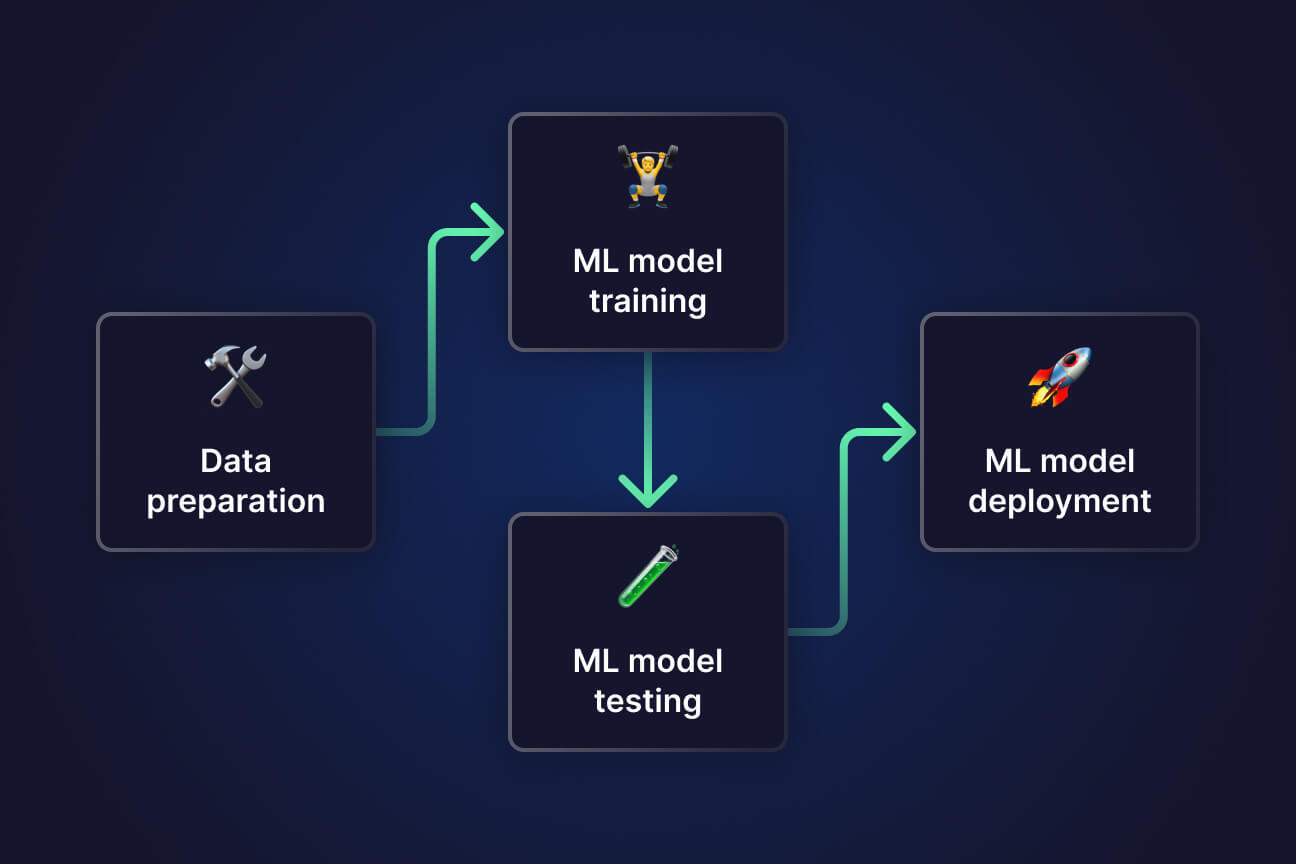
Machine learning projects often fail not because of bad algorithms but because of messy workflows. In this post, I share five lessons I’ve learned while improving my ML pipelines.
1. Start with Data Cleaning
Garbage in, garbage out. Handle missing values, outliers, and scaling before worrying about fancy models.
2. Automate Preprocessing
Use tools like scikit-learn Pipelines to standardize data transformations. This reduces human error and ensures reproducibility.
3. Modularize Your Code
Break your code into functions or classes. For example: one module for data loading, one for preprocessing, one for model training.
4. Track Experiments
Log parameters, metrics, and results. Tools like MLflow or even structured Excel sheets help compare experiments effectively.
5. Document Everything
Your future self (or your teammates) will thank you for leaving comments, README files, and notebooks that explain what’s going on.
Why This Matters
Clean pipelines save hours of debugging, make collaboration easier, and prepare your projects for deployment in real-world scenarios.
Closing Thought
Great ML isn’t just about accuracy—it’s about clarity, structure, and scalability. Cleaner pipelines are the foundation for serious data science.

1 Comment
Kia Hoffman
April 22, 2025“Seader will be distracted by the readable content of a page when looking at its layout. The point of using Lorem Ipsum is that it has a more-or-less normal distribution of letters.”